
Vous êtes-vous déjà demandé à quel point la recherche vocale sur Google était simple ? La réponse réside dans la technologie de reconnaissance automatique de la parole (ASR), qui traduit le langage parlé en texte en temps réel.
Alors que les outils de synthèse vocale de base se contentent de transcrire les mots, les systèmes ASR avancés exploitent l'intelligence artificielle et l'apprentissage automatique pour offrir une plus grande précision, reconnaître divers accents, filtrer le bruit de fond et saisir la signification contextuelle. Cela les rend indispensables pour les assistants virtuels, les robots de service client et les moteurs de recherche vocale.
Dans ce guide, nous expliquerons le fonctionnement de l'ASR, démystifierons les mythes courants, explorerons les utilisations du monde réel, telles que la suite de montage vidéo de Filmora, et présenterons les défis et opportunités futurs.
Dans cet article
- Qu'est-ce qu'un système de reconnaissance vocale automatique et comment fonctionne-t-il ?
- Mythes courants sur les systèmes ASR et faits
- Comment utiliser la technologie de reconnaissance vocale automatique
- Défis liés aux applications ASR et évolutions futures
Partie 1 :Qu'est-ce qu'un système de reconnaissance vocale automatique et comment fonctionnent-ils ?

Reconnaissance vocale automatique transforme les mots parlés en texte écrit en appliquant l'IA, l'apprentissage automatique et des modèles linguistiques pour analyser et interpréter les signaux audio. Il alimente les assistants vocaux comme Siri et Alexa, gère les services de transcription, prend en charge l'analyse des centres d'appels et sous-tend les outils de traduction en temps réel.
Le processus va au-delà de la simple écoute. Voici comment fonctionne généralement un système ASR :
Comment fonctionnent les systèmes ASR ?
- La parole est capturée via un microphone ou un fichier audio importé.
- Le prétraitement nettoie le signal, réduisant ainsi le bruit et améliorant la clarté.
- L'audio est segmenté en images courtes et des caractéristiques telles que la hauteur, le ton et le rythme sont extraites.
- Un modèle acoustique, entraîné sur de vastes corpus vocaux, mappe ces caractéristiques aux probabilités de phonèmes.
- Un modèle linguistique prédit les séquences de mots les plus probables en fonction de la grammaire, des expressions courantes et de la syntaxe, résolvant ainsi les ambiguïtés (par exemple, en distinguant "reconnaître la parole" de "détruire une belle plage").
- Un algorithme de décodage combine des preuves acoustiques et linguistiques pour produire la transcription finale, souvent en millisecondes.
Les systèmes ASR de pointe utilisent des réseaux neuronaux profonds qui affinent continuellement les prédictions à mesure qu'ils apprennent des corrections des utilisateurs, améliorant ainsi progressivement la précision.
Partie 2 :Mythes courants sur les systèmes ASR et faits
Malgré une adoption généralisée, des idées fausses persistent concernant les capacités ASR.

| Mythes | Faits |
| Les systèmes ASR sont précis à 100 % | Même les principaux modèles, tels que Speech-to-Text de Google et Whisper d'OpenAI, interprètent parfois mal le discours en raison du bruit de fond ou des accents atypiques. La post-édition reste recommandée, en particulier pour les applications critiques. |
| Les systèmes ASR comprennent le langage comme les humains | ASR repose sur la correspondance de modèles statistiques plutôt que sur la compréhension sémantique. Il mappe les sons aux mots à l'aide de modèles probabilistes (HMM, réseaux neuronaux profonds), mais manque d'une véritable compréhension du sens. |
Partie 3 :Comment utiliser la technologie de reconnaissance vocale automatique
Au-delà des commandes vocales, ASR est intégré aux outils industriels pour rationaliser les flux de travail. Vous trouverez ci-dessous une présentation pratique de l'utilisation de l'ASR dans Filmora, une plateforme de montage vidéo populaire.
Logiciel de montage vidéo avec ASR – Filmora
La fonction de détection de locuteurs basée sur l'IA de Filmora identifie automatiquement les voix distinctes dans une vidéo, générant des légendes ou des sous-titres précis. Cela fait gagner beaucoup de temps aux éditeurs et améliore l'accessibilité.

Utilisation du workflow ASR mobile de Filmora :
- Ouvrez Filmora sur votre téléphone et démarrez un nouveau projet. Importez la vidéo.
- Appuyez sur Texte → Légendes IA .
- Spécifiez la langue parlée ou laissez Filmora détecter automatiquement, puis cliquez sur Ajouter des sous-titres. . Le système analysera les intervenants et générera des sous-titres.
- Sélectionnez un modèle de légende via Modèle et appliquez-le aux légendes souhaitées.
- Ajustez l'emplacement des légendes en faisant glisser et modifiez le style du texte à l'aide de la barre d'outils.
- Pour affiner votre texte, cliquez sur Modifier le discours. pour corriger des erreurs ou cloner une voix, puis appuyez sur Mettre à jour la parole. .
Sur ordinateur, le processus reflète la version mobile mais utilise la fonction Speech‑to‑Text. fonctionnalité :
- Lancez Filmora et créez un nouveau projet. Ajoutez votre vidéo à la timeline.
- Cliquez avec le bouton droit sur le clip et sélectionnez Speech-to-Text. .
- Choisissez des titres comme format de sortie et cliquez sur Générer .
- Le texte transcrit apparaît sous forme de légendes modifiables sur la chronologie.
Partie 4 : Défis liés aux applications ASR et progressions futures

Même si l'ASR a transformé de nombreuses tâches, plusieurs obstacles demeurent :
- Accents et dialectes : La prononciation, l'intonation et l'argot régional peuvent conduire à une mauvaise interprétation.
- Qualité audio :Le bruit de fond, les échos et les sons qui se chevauchent dégradent la précision de la transcription.
- Homophones : Les mots qui semblent identiques mais dont le sens diffère (par exemple, "là", "leur", "ils sont") peuvent confondre les systèmes sans indices contextuels.
Relever ces défis implique de développer des modèles acoustiques plus robustes qui englobent un spectre plus large de variations de la parole et d'intégrer le traitement du langage naturel pour fournir une désambiguïsation contextuelle.
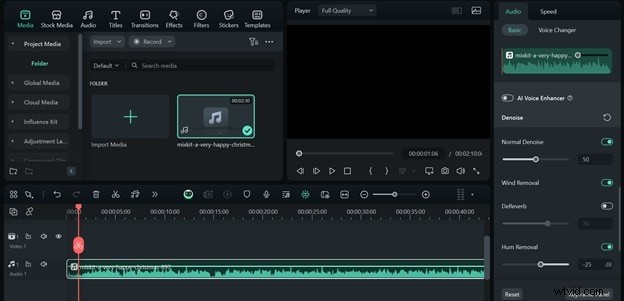
Améliorer la qualité audio avec Filmora
Pour les outils ASR qui acceptent les téléchargements audio, Filmora propose des fonctionnalités de suppression du bruit :
- Importez le clip audio dans la timeline.
- Sélectionnez le clip, ouvrez le panneau de l'éditeur et activez la normalisation automatique. , Dénoise , Suppression du vent et Suppression du bourdonnement .
- Exportez l'audio nettoyé au format MP3 pour des performances ASR optimales.
Conclusion
Reconnaissance vocale automatique remodèle la façon dont nous interagissons avec la technologie, des simples transcriptions aux solutions industrielles sophistiquées. Des outils comme Filmora illustrent comment ASR peut automatiser le sous-titrage et le nettoyage audio, améliorant ainsi la productivité et l'accessibilité.
Malgré les obstacles existants, les progrès continus de l'IA et de la PNL promettent une reconnaissance vocale encore plus précise et polyvalente dans un avenir proche.

Filmora
⭐⭐⭐⭐⭐
Les meilleurs logiciels et applications de montage vidéo basés sur l'IA