La conversion de la parole en texte n'a jamais été aussi simple, grâce aux modèles parole-texte de Hugging Face. Que vous transcriviez des entretiens, génériez des sous-titres ou développiez des applications basées sur l'IA, Hugging Face offre une reconnaissance vocale de pointe optimisée par des modèles avancés d'apprentissage automatique. La meilleure partie ? Il est hautement personnalisable, vous permettant d'affiner les modèles pour une meilleure précision et de meilleures performances en fonction de vos besoins spécifiques.
Dans ce guide, nous vous expliquerons comment configurer et utiliser l'API Hugging Face de synthèse vocale. , explorez ses options de personnalisation et discutez de cas d'utilisation pratiques. Mais que se passe-t-il si vous avez besoin d’une alternative plus simple ? Ne vous inquiétez pas, nous présenterons également un outil de synthèse vocale facile à utiliser qui permet d'effectuer le travail sans effort. Que vous soyez développeur, créateur de contenu ou professionnel, ce guide vous aidera à trouver la meilleure solution de synthèse vocale pour votre flux de travail. Continuez à lire.
Dans cet article
- Fonctionnement de la synthèse vocale des câlins
- Configurer la synthèse vocale d'un visage câlin
- Une alternative plus simple :la synthèse vocale automatique avec Filmora
- Quel outil est le meilleur
Partie 1 :Comment fonctionne la synthèse vocale avec un visage câlin
Hugging Face Speech-to-Text est une fonctionnalité intéressante de la bibliothèque Hugging Face Transformers qui vous permet de transformer des mots prononcés en texte écrit à l'aide de modèles pré-entraînés. Il utilise la technologie avancée de reconnaissance automatique de la parole (ASR) pour transcrire la parole. Avec des architectures basées sur des transformateurs comme Wav2Vec2, le système traite les données audio et les convertit en texte. Et il le fait avec une grande précision.
L'une des choses qui font de la Speech-to-Text in Hugging Face se démarque par son intégration de pipeline qui le rend très simple pour les développeurs. Avec seulement quelques lignes de code, vous pouvez traiter des fichiers audio et obtenir des transcriptions de texte. En outre, il dispose de modèles pré-entraînés pour plusieurs langues et scénarios vocaux, ce qui le rend adaptable à de nombreux cas d'utilisation.
Le processus de conversion parole-texte suit une séquence étape par étape pour garantir une transcription précise :
- Entrée audio :vous fournissez un fichier audio à traiter.
- Extraction de fonctionnalités :le système extrait les fonctionnalités vocales et les banques de filtres log-mel. Cela permet d'analyser les modèles sonores.
- Inférence de modèle :un modèle de transformateur pré-entraîné traite les caractéristiques et génère des jetons de texte qui représentent des mots prononcés.
- Sortie texte :le modèle convertit ces jetons en une transcription textuelle.
Les modèles de synthèse vocale Hugging Face, en particulier SeamlessM4T-v2, améliorent l'efficacité en implémentant un cadre double séquence à séquence (seq2seq). Il dispose d'encodeurs de parole et de texte séparés, ainsi que d'un vocodeur HiFi-GAN, qui améliore la qualité de la voix générée. Il s'agit d'un outil utile pour la reconnaissance et l'automatisation vocales, avec des applications telles que des assistants virtuels, des sous-titres en direct, des services de transcription et une recherche vocale.
Partie 2 : Configurer la parole en texte avec un visage câlin
Vous trouverez ci-dessous un guide étape par étape sur la configuration afin d'utiliser la synthèse vocale avec visage câlin :
Étape 1 :Créer un compte Hugging Face

La première chose dont vous avez besoin est un compte sur Hugging Face. La création d'un compte vous donne accès à des modèles et des API pré-entraînés. Si vous n'avez pas déjà de compte ;
- Accéder au site Web de Hugging Face
- Cliquez sur S'inscrire
- Saisissez vos coordonnées et créez un compte
- Une fois connecté, accédez aux paramètres de votre profil
- Recherchez des jetons d'accès et créez un nouveau jeton (choisissez "Écrire" comme niveau d'autorisation)
Ce jeton vous aidera à vous connecter à Hugging Face à partir de votre code.
Étape 2 :Installer les bibliothèques requises
La prochaine chose que vous devez faire est d’installer toutes les bibliothèques dont vous aurez besoin. Pour ce faire, ouvrez votre terminal ou votre invite de commande et tapez :
pip installer les ensembles de données des transformateurs torchaudio librosa soundfile
Transformers permet de charger des modèles Hugging Face, torchaudio aide à traiter les données audio, tandis que librosa et soundfile aident à charger et modifier des fichiers audio.
Étape 3 :Charger le modèle
Après avoir installé toutes les bibliothèques requises, la prochaine chose que vous devez faire est de charger le modèle parole-texte. Vous pouvez utiliser Wav2Vec2 car c'est l'un des meilleurs modèles pré-entraînés pour la reconnaissance vocale.
à partir des transformateurs import Wav2Vec2ForCTC, Wav2Vec2Processor
importer une torche
# Charger le modèle et le processeur
nom_modèle ="facebook/wav2vec2-large-960h"
processeur =Wav2Vec2Processor.from_pretrained(model_name)
modèle =Wav2Vec2ForCTC.from_pretrained(model_name)
Étape 4 : Convertir l'audio en texte
Vous devez préparer votre fichier audio pour que le modèle puisse le comprendre. Pour y parvenir, vous devez charger l'audio dans votre logiciel. Ensuite, assurez-vous qu'il est au bon format afin que le modèle puisse le traiter de manière appropriée. Vous l'exécuterez dans le modèle pour transformer le discours en texte.
importer librosa
#Charger un fichier audio et convertir en 16kHz
def load_audio(file_path):
audio, sr =librosa.load(file_path, sr=16000)
renvoyer l'audio
fichier_audio ="exemple.wav"
audio_input =load_audio(audio_file)
Traitez l'entrée audio pour que le modèle puisse la lire
input_values =processeur (audio_input, return_tensors="pt", sampling_rate=16000).input_values

Remarque : Pour les projets plus importants, Hugging Face propose un point de terminaison API qui vous permet de traiter la parole à distance sans gérer le modèle sur votre propre appareil. Inscrivez-vous simplement à un compte Hugging Face, obtenez une clé API et envoyez des fichiers audio via une simple requête API.
Comment personnaliser les modèles de synthèse vocale
Si vous souhaitez que votre modèle de reconnaissance vocale en texte fonctionne mieux, vous devez l'affiner. Le modèle de base est bon, mais il peut ne pas comprendre certains accents, bruits de fond ou mots spéciaux. L'entraîner avec vos propres données l'aide à apprendre et à s'améliorer, ce qui le rend beaucoup plus précis pour vos besoins. Voici comment affiner le modèle :
- Affinez les réglages avec des données personnalisées :entraînez le modèle avec vos propres ensembles de données audio et de transcription pour améliorer la reconnaissance d'accents ou de termes spécifiques du secteur.
- Ajuster les paramètres d'inférence :modifiez des paramètres tels que la température et la recherche de faisceaux pour affiner la précision.
- Ajouter un vocabulaire personnalisé :apprenez au modèle de nouveaux mots et expressions pertinents pour votre domaine.
La personnalisation rend le modèle plus précis et fiable pour vos besoins spécifiques. Mais si vous préférez une solution plus simple, consultez la section suivante pour une alternative simple à la synthèse vocale !
Partie 3 : Une alternative plus simple :la synthèse vocale automatique avec Filmora
Hugging Face Speech-to-Text semble trop compliqué et nécessite des compétences techniques comme le codage. Mais il existe une alternative plus simple :Wondershare Filmora est une approche beaucoup plus simple pour convertir la parole en texte. Filmora est un logiciel de montage vidéo populaire doté d'un outil de synthèse vocale qui transcrit automatiquement l'audio en quelques clics.
- Filmora simplifie tout pour vous. Vous n'avez donc pas besoin de compétences en programmation ni de configurations complexes.
- Il peut transcrire la parole vidéo en texte avec une précision allant jusqu'à 99 %. Ainsi, les créateurs de contenu, les étudiants et même les professionnels peuvent l'utiliser pour générer du texte à partir de l'audio de manière rapide et précise.
- Prend en charge plus de 45 langues et convient parfaitement aux sous-titres vidéo, aux notes vocales et aux interviews.
- Il est équipé de la traduction automatique des sous-titres pour le contenu multilingue
- Vous pouvez générer des légendes animées personnalisables pour améliorer l'engagement
- De plus, la fonctionnalité de synthèse vocale intégrée de Filmora traite les données audio très rapidement et fait gagner du temps à l'utilisateur. Sa rapidité et son gain de temps en font la meilleure alternative.
Partie 4 :Comment utiliser la synthèse vocale de Filmora
Filmora simplifie grandement la conversion de la parole en texte. Il n'est pas nécessaire de créer du code ou de configurer quoi que ce soit de difficile.
Suivez simplement ces instructions simples pour obtenir votre transcription en un rien de temps grâce à la fonctionnalité parole-texte du bureau :
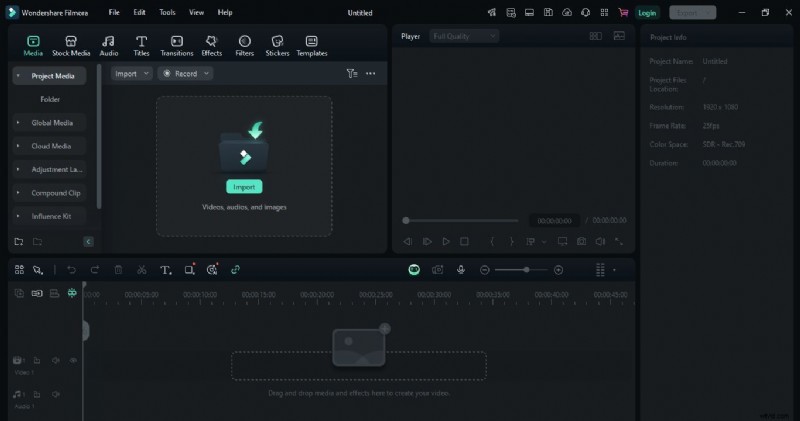
Étape 1 :Importez votre audio ou votre vidéo
Ouvrez Filmora et ajoutez votre fichier audio ou vidéo. Vous pouvez le faire simplement en le faisant glisser et en le déposant sur la timeline. Cela vous facilite la tâche. Une fois votre dossier en place, vous êtes prêt à passer à autre chose.
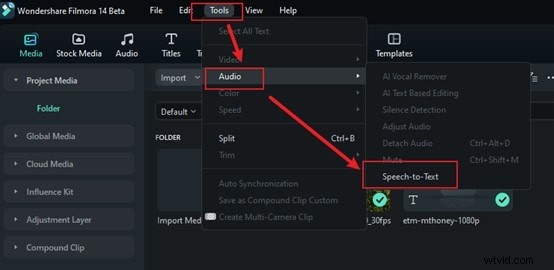
Étape 2 : Sélectionnez l'option de synthèse vocale
Accédez aux Outils dans la barre de menu supérieure et cliquez dessus. Choisissez Audio, puis l'option Text to Speech pour analyser automatiquement votre audio. Pas besoin d'ajuster les paramètres ou de faire quoi que ce soit de plus car il gère tout pour vous.
Étape 3 :Choisissez votre langue
Filmora prend en charge de nombreuses langues, alors choisissez celle qui correspond à votre audio. Cette étape est importante car choisir la bonne langue aide Filmora à retranscrire votre discours avec précision. Si vous ignorez cette étape, vous risquez d'obtenir des résultats incorrects.
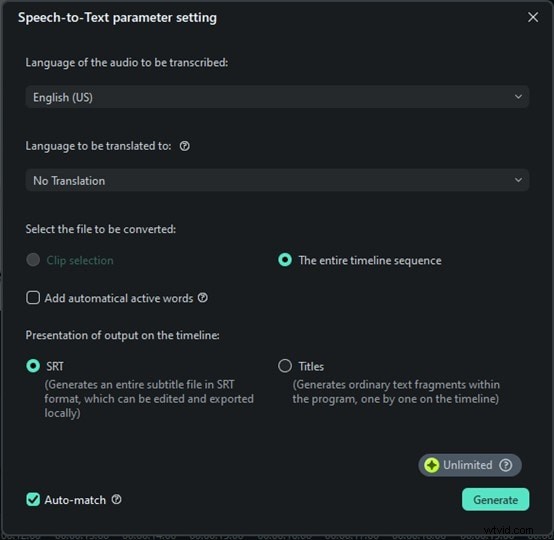
Étape 4 :Démarrez la transcription et enregistrez
Maintenant, cliquez simplement sur Générer et Filmora commencera à transcrire votre discours. Cette partie est vraiment rapide. En quelques secondes, vous verrez les mots prononcés apparaître sous forme de texte. Pas d'attente pendant des heures, pas de configuration complexe, juste des résultats instantanés. Cliquez sur le fichier texte, sélectionnez Exporter la transcription du fichier de sous-titres pour l'enregistrer et l'ajouter comme sous-titres à votre vidéo.
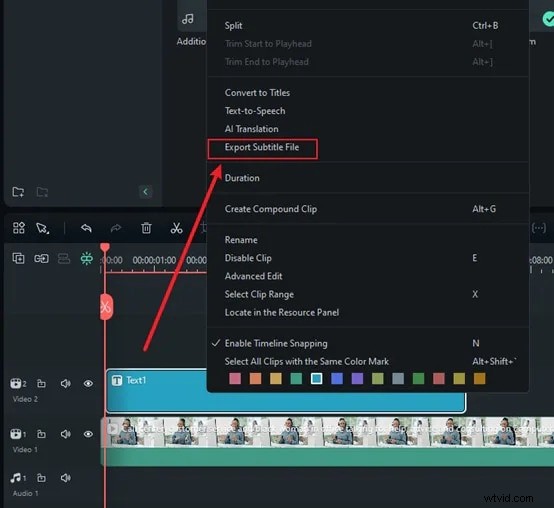
Si vous souhaitez convertir le discours vidéo en sous-titres de texte, Filmora propose également une fonctionnalité de sous-titrage IA sur son application mobile. Il vous permet de générer des légendes de texte sur votre appareil mobile en moins d'une minute
Étape 1 :Téléchargez l'application Filmora depuis le Google Play Store (Android) ou l'App Store (iPhone). Vous pouvez également l'obtenir sur le site officiel. Une fois installé, ouvrez l'application et appuyez sur Nouveau projet.
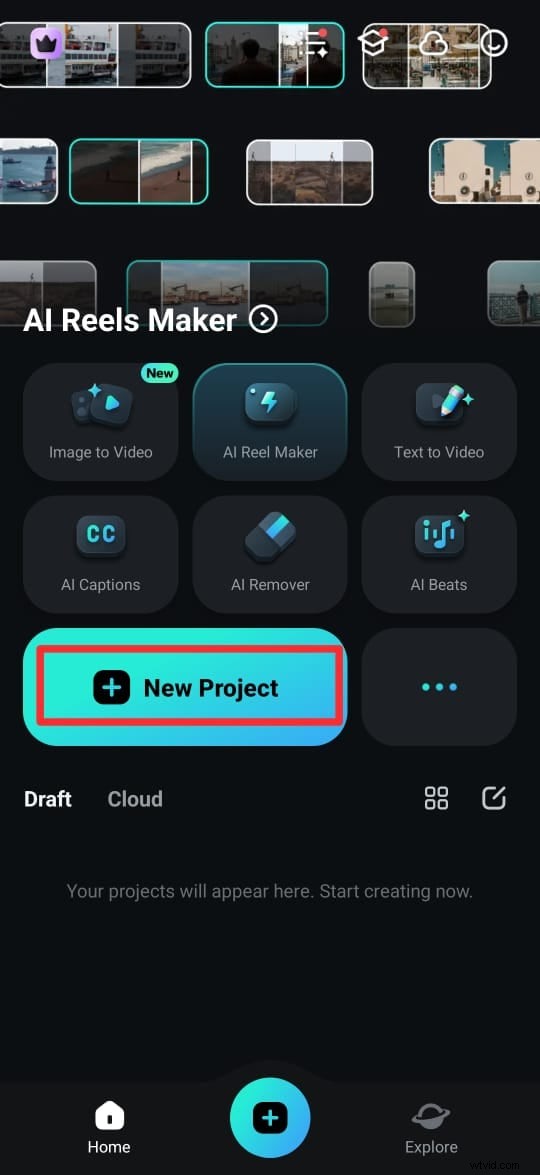
Étape 2. Choisissez une vidéo dans votre bibliothèque multimédia et appuyez sur Importer pour l'ajouter à votre espace de travail.

Étape 3 :Dans le menu du bas, appuyez sur Texte (marqué par une icône T) et choisissez Légendes AI.
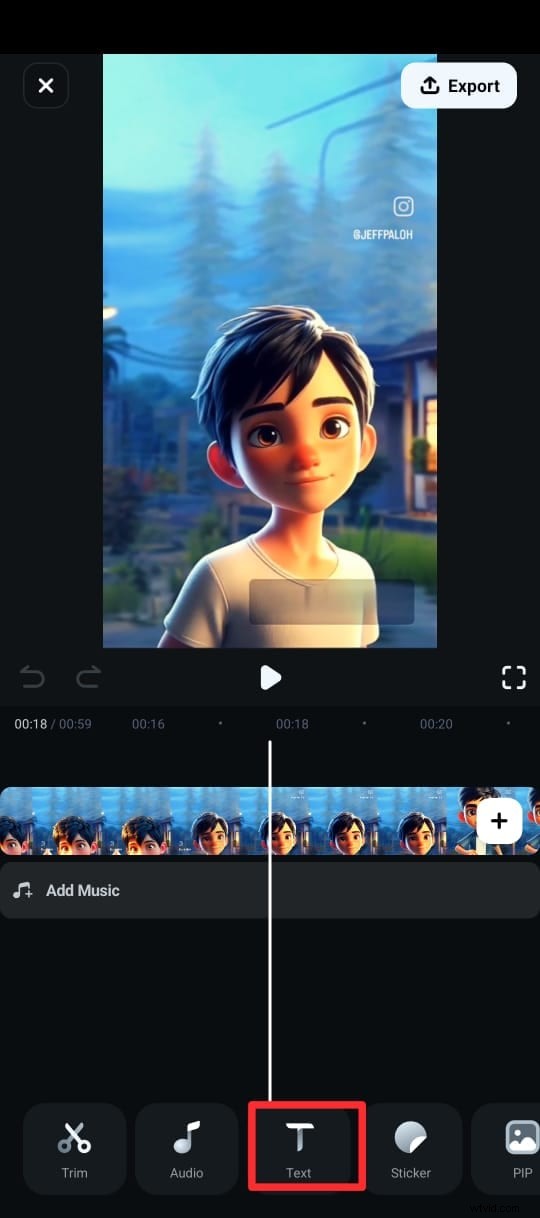
Étape 4 :Sur l'écran suivant, sélectionnez la langue, activez Détection du locuteur et appuyez sur Ajouter des sous-titres pour générer du texte à partir du discours de la vidéo.
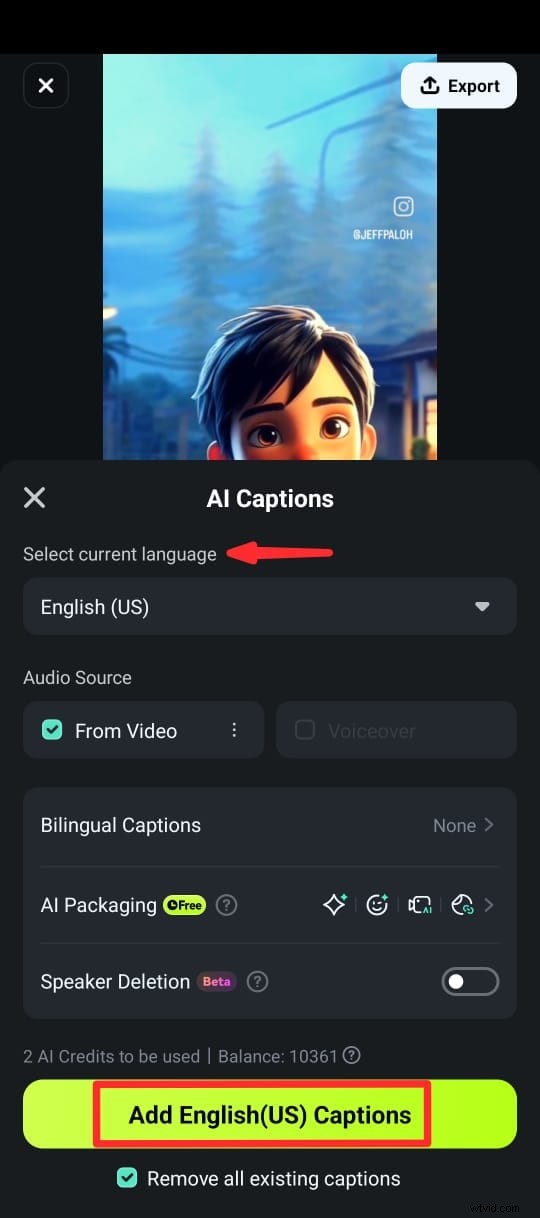
Étape 5 :Une fois les légendes générées, vous pouvez personnaliser le texte à l'aide de différents modèles de texte, emojis et polices. Vous pouvez également modifier le texte du clip dans la timeline en sélectionnant Modifier la parole dans la suite d'édition.
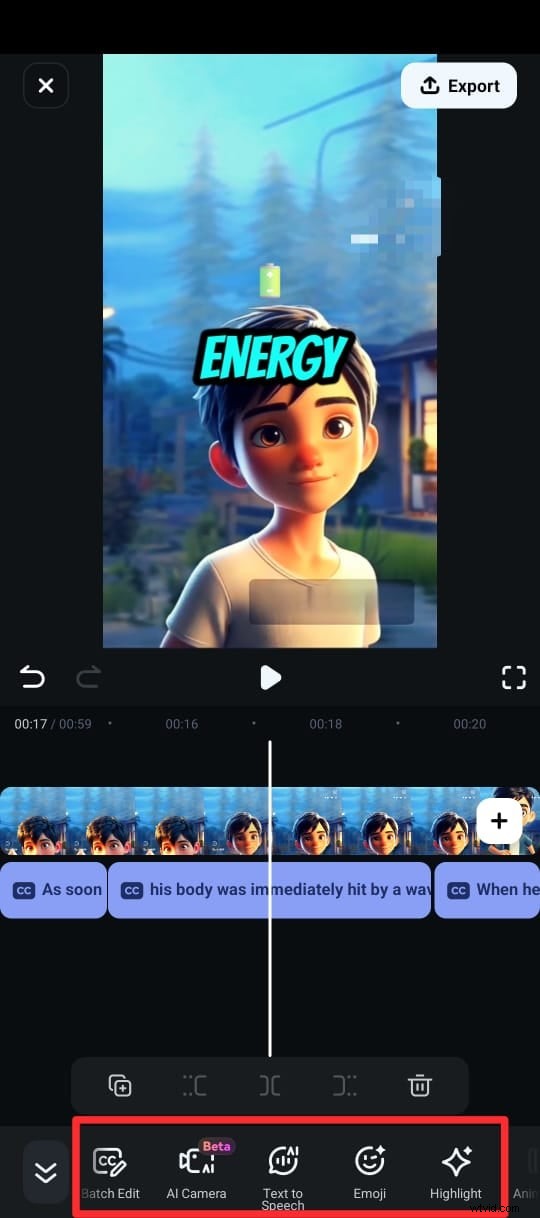
Étape 6 :Exportez votre vidéo avec les sous-titres au format souhaité.
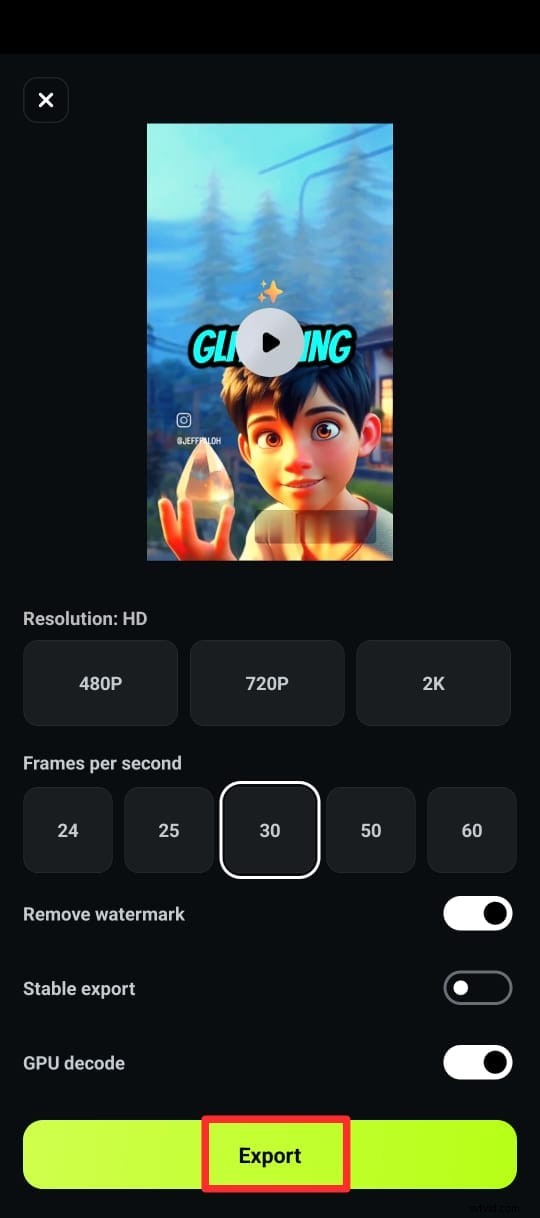
Partie 5. Quel outil est le meilleur ?
Le choix entre Hugging Face et Filmora dépend de vos besoins spécifiques et de votre niveau d’expertise technique. Chaque outil répond à un objectif différent, alors explorons celui qui vous convient le mieux en fonction de différents scénarios.
- Si vous avez besoin d'une personnalisation avancée et d'un contrôle basé sur l'IA, la synthèse vocale Hugging Face est le meilleur choix. Il est idéal pour les développeurs, les chercheurs et les professionnels qui souhaitent former des modèles, affiner les paramètres et travailler avec de grands ensembles de données. Cependant, sa configuration nécessite des connaissances en codage et du temps, ce qui la rend moins adaptée aux débutants ou à ceux qui recherchent une solution rapide.
- D'un autre côté, si vous souhaitez un outil de transcription rapide et précis sans aucune configuration technique, Filmora est la solution idéale. Il est conçu pour les créateurs de contenu, les étudiants et les professionnels qui ont besoin d'une solution simple en un clic.
- Utilisez Filmora si vous ajoutez des sous-titres/légendes à des vidéos, transcrivez des cours ou convertissez un discours en texte pour des rapports.
- Pour ceux qui travaillent dans des domaines de niche qui nécessitent une reconnaissance vocale spécifique à un domaine, Hugging Face vous permet d'entraîner le modèle sur la terminologie spécifique au secteur. Cela garantit une meilleure précision pour le jargon complexe, mais encore une fois, cela nécessite des efforts et un savoir-faire technique.
- En attendant, si votre objectif principal est de transcrire du contenu vidéo, Filmora est une option plus pratique, car il convertit rapidement la parole en texte, ce qui le rend idéal pour les YouTubeurs, les podcasteurs et les créateurs de réseaux sociaux.
En résumé, si vous aimez coder et souhaitez un contrôle et une personnalisation complets, optez pour la synthèse vocale dans huggingface. Mais si vous souhaitez un outil de transcription simple et instantané, Filmora est le choix parfait. Choisissez celui qui correspond le mieux à votre flux de travail et à votre niveau de compétence.
Conclusion
La conversion de la parole en texte ne doit pas être compliquée. Synthèse vocale du visage câlin est un outil puissant mais nécessite un codage et une configuration, ce qui est intéressant pour les développeurs. Cependant, si vous voulez quelque chose de rapide et facile, Filmora est la meilleure alternative. En quelques clics, vous pouvez transcrire l'audio sans effort; pas de codage, pas de stress. Pourquoi passer des heures sur des configurations complexes ? Essayez la fonctionnalité de synthèse vocale de Filmora dès aujourd'hui et convertissez votre audio en texte en quelques secondes