Vous montez une vidéo avec plusieurs intervenants, peut-être un podcast ou une interview. L'ajout manuel de sous-titres est fastidieux :vous devez écouter, saisir et synchroniser chaque mot prononcé. Et si votre éditeur vidéo pouvait reconnaître automatiquement différentes voix et générer des sous-titres pour chaque intervenant ? C'est là que la reconnaissance du locuteur en Python change la donne.
Python est le langage de programmation de premier choix pour développer des applications vocales en raison de ses bibliothèques robustes. Ces bibliothèques vous aident à implémenter et à déployer des modèles de reconnaissance du locuteur pour le traitement, l'analyse et l'identification de la parole en temps réel. Par exemple, le SDK Pico Voice Eagle permet une identification rapide et précise des locuteurs pour les applications basées sur l'IA.
Alternativement, il existe des plateformes de montage vidéo qui intègrent l’intelligence artificielle de reconnaissance vocale. Ils fonctionnent en analysant l'audio de la vidéo, en distinguant les intervenants et en générant des sous-titres synchronisés.
Ce guide explorera comment implémenter l'identification du locuteur en Python. Nous examinerons également les meilleures alternatives sans code pour un sous-titrage vidéo sans effort.

Dans cet article
- Principes fondamentaux du traitement audio
- Identification des locuteurs en temps réel avec le SDK Picovoice Eagle
- Existe-t-il des moyens plus simples d'effectuer la reconnaissance du locuteur ?
- Où puis-je utiliser les applications de reconnaissance du locuteur ?
Partie 1 : Fondamentaux du traitement audio

Chaque système de reconnaissance vocale commence par le traitement audio. Le son se propage sous forme de signaux analogiques continus, mais les ordinateurs nécessitent des formats numériques. Pour convertir la parole en données, nous utilisons des taux d'échantillonnage et des techniques d'encodage audio.
Un taux d'échantillonnage définit la fréquence à laquelle le son est enregistré par seconde. La norme pour la reconnaissance des locuteurs Python est de 16 kHz, garantissant une grande précision. Le format du fichier audio est également important :WAV, MP3 et FLAC sont des options courantes, WAV étant préféré pour les tâches d'apprentissage automatique.
Python simplifie l'identification des locuteurs en temps réel avec des bibliothèques spécialisées telles que PyAudio et Picovoice Eagle SDK. Grâce à ces outils, les développeurs peuvent capturer, analyser et entraîner des modèles pour l'identification des locuteurs en temps réel en Python.
Partie 2 :Identification des locuteurs en temps réel avec le SDK Picovoice Eagle
Picovoice Eagle SDK est un outil hautes performances pour la reconnaissance des locuteurs en Python . Contrairement aux modèles traditionnels, il traite l'audio localement. Ce SDK est crucial pour l'identification des locuteurs en temps réel en Python, en particulier dans les systèmes de sécurité IA et les assistants intelligents.
De plus, il est léger et fonctionne de manière transparente sur plusieurs plates-formes, notamment Windows, macOS, Linux, Android, iOS et même Raspberry Pi. Il vous suffit de vous inscrire à la console Pico Voice et d'obtenir votre clé d'accès pour authentifier votre utilisation.
Installation et configuration du SDK Pico Voice Eagle en Python
Pour intégrer le SDK Picovoice Eagle pour la reconnaissance des locuteurs dans Python, installez-le d'abord. Avant de faire cela, assurez-vous que Python 3.6+ est installé.
Ouvrez un terminal (Linux/macOS) ou une invite de commande (Windows) et exécutez :
ou
Si Python est installé, il affichera quelque chose comme :
Si la version est 3.6 ou supérieure, vous êtes prêt à partir.
Pour commencer, installez les bibliothèques nécessaires. Exécutez ce qui suit dans votre terminal :
pip install SpeechRecognition pyaudio librosa pvrecorder
Pour le SDK Picovoice Eagle, téléchargez et installez :
pip install pvporcupine pveagle
Guide étape par étape pour la mise en œuvre de l'identification des locuteurs en temps réel à l'aide du SDK Picovoice Eagle en Python
- Étape 1 :Installez Python. Sur le site Web officiel de Python, sélectionnez l'option permettant de télécharger la version la plus récente, Python 3. x.x.
- Étape 2 : Ensuite, créez un compte gratuit sur la console Picovoice et récupérez votre clé d'accès. Cette clé est requise pour authentifier vos demandes lors de l'utilisation du SDK Eagle Speaker Recognition.
- Étape 3 : Installez les packages Python nécessaires. Exécutez la commande suivante dans votre terminal :
pip install pveagle pvrecorder
Cela installera PV Eagle (pour la reconnaissance des locuteurs) et PV Recorder (pour la capture audio).
- Étape 4 : Créez deux fichiers dans votre VsCode. Le premier dossier sera d'inscrire un intervenant. L'inscription est le processus de création d'un profil de locuteur basé sur des données vocales. Suivez ces étapes :
- Importer les bibliothèques requises
- Initialisez EagleProfile avec votre clé d'accès
- Utiliser PV Recorder pour capturer des échantillons de voix
- Envoyer des images audio à EagleProfile jusqu'à ce que l'inscription soit terminée
- Exporter le profil de l'intervenant pour une reconnaissance future
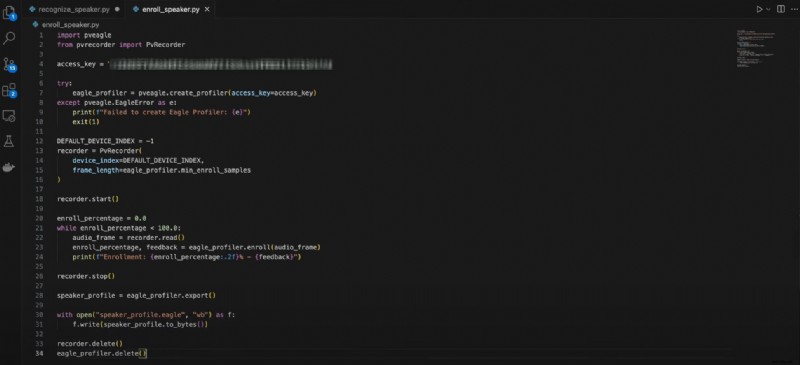
Voici le code d'inscription des conférenciers :
importer pveagleà partir de pvrecorder importer PvRecorder
access_key ="VOTRE_ACCESS_KEY"
essaye :
eagle_profiler =pveagle.create_profiler(access_key=access_key)
sauf pveagle.EagleError comme e :
print(f"Échec de la création d'Eagle Profiler :{e}")
quitter(1)
DEFAULT_DEVICE_INDEX =-1
enregistreur =PvEnregistreur(
appareil_index=DEFAULT_DEVICE_INDEX,
frame_length=eagle_profiler.min_enroll_samples
)
enregistreur.start()
inscription_pourcentage =0,0
tandis que enroll_percentage <100,0 :
audio_frame =enregistreur.read()
enroll_percentage, feedback =eagle_profiler.enroll(audio_frame)
print(f"Inscription :{enroll_percentage:.2f}% - {feedback}")
enregistreur.stop()
Speaker_profile =eagle_profiler.export()
avec open("speaker_profile.eagle", "wb") comme f :
f.write(speaker_profile.to_bytes())
enregistreur.delete()
eagle_profiler.delete()
- Étape 5 :Accédez à votre terminal et enregistrez en saisissant le code ci-dessous
python3 enroll_speaker.py
Une fois le script exécuté, essayez de parler dans le microphone. Si votre voix correspond au profil de locuteur inscrit, le message « Locateur reconnu ! » s'affichera. Sinon, cela indiquera un locuteur inconnu.

- Étape 6 : Maintenant que le profil de l'orateur est prêt, créons un code pour la reconnaissance de l'orateur en temps réel sur le deuxième fichier. Cela charge un profil de locuteur et reconnaît un locuteur en temps réel à l'aide du SDK Pico Voice Eagle.
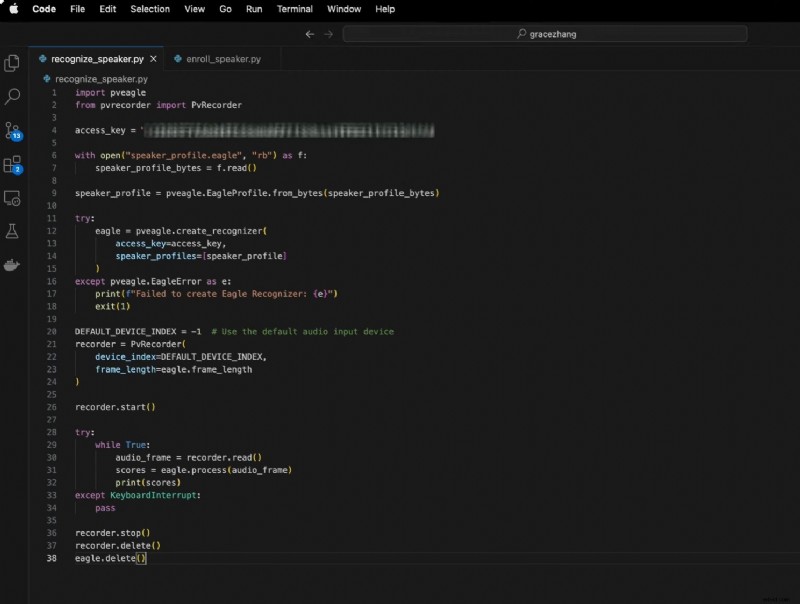
Cela implique :
- Créer une instance Eagle avec votre clé d'accès et votre profil de conférencier
- Utiliser PV Recorder pour capturer de l'audio en direct
- Transmission des images audio à Eagle pour une reconnaissance en temps réel
Voici le code :
importer pveagleà partir de pvrecorder importer PvRecorder
access_key ="VOTRE_ACCESS_KEY"
avec open("speaker_profile.eagle", "rb") comme f :
speaker_profile_bytes =f.read()
speaker_profile =pveagle.EagleProfile.from_bytes(speaker_profile_bytes)
essaye :
aigle =pveagle.create_recognizer(
access_key=access_key,
speaker_profiles=[speaker_profile]
)
sauf pveagle.EagleError comme e :
print(f"Échec de la création d'Eagle Recognizer :{e}")
quitter(1)
DEFAULT_DEVICE_INDEX =-1 # Utiliser le périphérique d'entrée audio par défaut
enregistreur =PvEnregistreur(
appareil_index=DEFAULT_DEVICE_INDEX,
frame_length =aigle.frame_length
)
enregistreur.start()
essaye :
tandis que Vrai :
audio_frame =enregistreur.read()
scores =eagle.process (audio_frame)
imprimer(partitions)
sauf KeyboardInterrupt :
passer
enregistreur.stop()
enregistreur.delete()
aigle.delete()
- Étape 7 :tester et exécuter l'application.
Python3 recognize_speaker.py
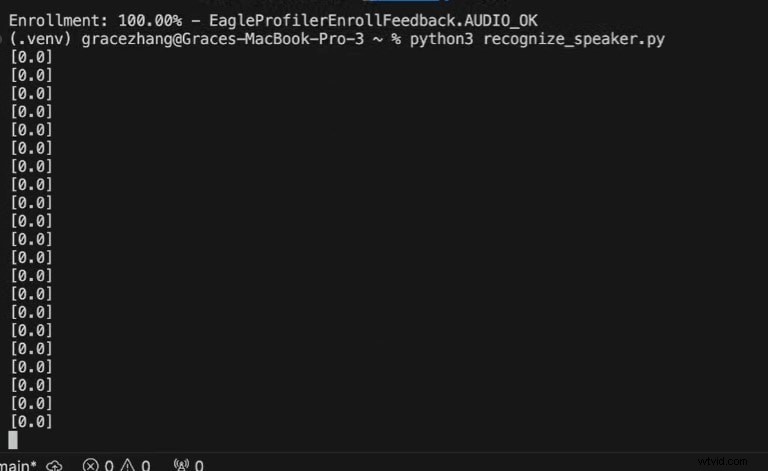
0 =Voix non reconnue
1 =Voix reconnue

Remarque :Contrairement aux modèles basés sur le cloud, le SDK Picovoice Eagle traite les données localement. Cela garantit des résultats plus rapides, une meilleure confidentialité et aucune dépendance à Internet.
L'identification du locuteur en Python ne peut être comprise et exécutée que par des programmeurs professionnels. Vous devez avoir une certaine connaissance en programmation pour comprendre le processus.
Partie 3 :Existe-t-il des moyens plus simples d'effectuer la reconnaissance du locuteur ?
Construire un système de reconnaissance de locuteurs Python nécessite des compétences en codage et des connaissances techniques. Bien que l’identification en Python soit puissante, elle peut s’avérer difficile pour les non-programmeurs. De nombreux utilisateurs préfèrent des outils prêts à l’emploi offrant des fonctionnalités similaires de reconnaissance vocale et de locuteur. C'est une meilleure façon d'accomplir la tâche sans compétences en codage.
L'un de ces outils est WondershareFilmora, un éditeur vidéo avec reconnaissance du locuteur et édition vocale intégrées. Il permet aux utilisateurs de détecter, transcrire et modifier des enregistrements vocaux sans écrire une seule ligne de code.
Contrairement à la reconnaissance du locuteur Python, qui nécessite une formation manuelle du modèle, les outils intégrés de Filmora automatisent le processus. Vous pouvez éditer et améliorer des fichiers audio sans avoir besoin de connaissances en Python ou en apprentissage automatique. Cela rend l'identification des locuteurs accessible aux créateurs de contenu, aux spécialistes du marketing et aux utilisateurs professionnels.
Fonctionnalités mobiles de détection des locuteurs et d'édition vocale de Filmora
Filmora intègre un outil basé sur l'IA qui simplifie l'édition audio et la reconnaissance des locuteurs. Avec sa version mobile, les utilisateurs peuvent accéder aux fonctionnalités de détection du locuteur et d'édition de la parole.
- Détection des haut-parleurs. La détection des haut-parleurs analyse le son et fait la distinction entre les différents haut-parleurs. Au lieu de la méthode manuelle d'écoute et de marquage des voix, l'IA identifie qui parle et quand.
- Modification du discours. L'édition du discours peut être fastidieuse, mais Speech Edit de Filmora simplifie le processus. Il permet aux utilisateurs de modifier les enregistrements vocaux, d'ajuster la clarté et de supprimer le bruit de fond.
Comment reconnaître la voix, convertir en texte et éditer à l'aide de Filmora en déplacement
Filmora simplifie la reconnaissance des locuteurs en quelques clics. Voici un guide étape par étape :
- Étape 1 :Téléchargez Filmora, cliquez sur « nouveau projet » et importez la vidéo avec la voix.
- Étape 2 :Sélectionnez le texte pour convertir les mots prononcés en texte.

- Étape 3 : Cliquez sur les sous-titres IA pour démarrer le processus de reconnaissance vocale
- Étape 4 : Cliquez sur l'option Détection du locuteur avant de sélectionner Ajouter des sous-titres
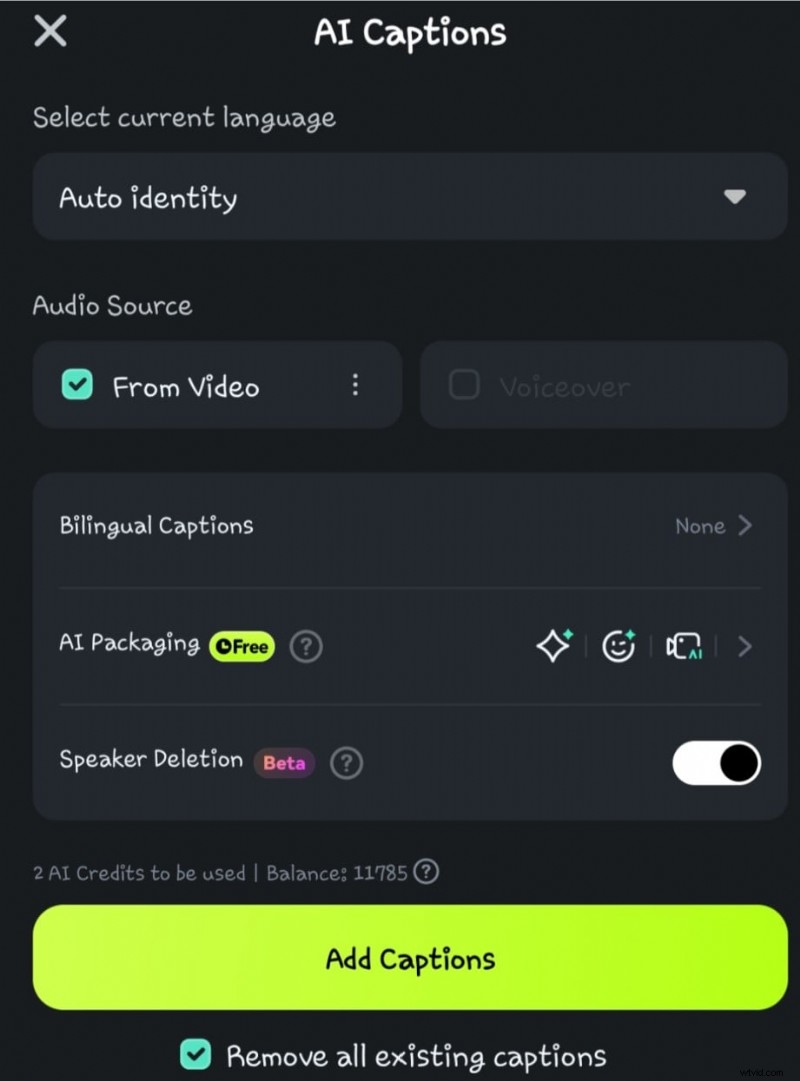
- Étape 5 : Attendez pendant que l'IA traite la conversion voix-texte
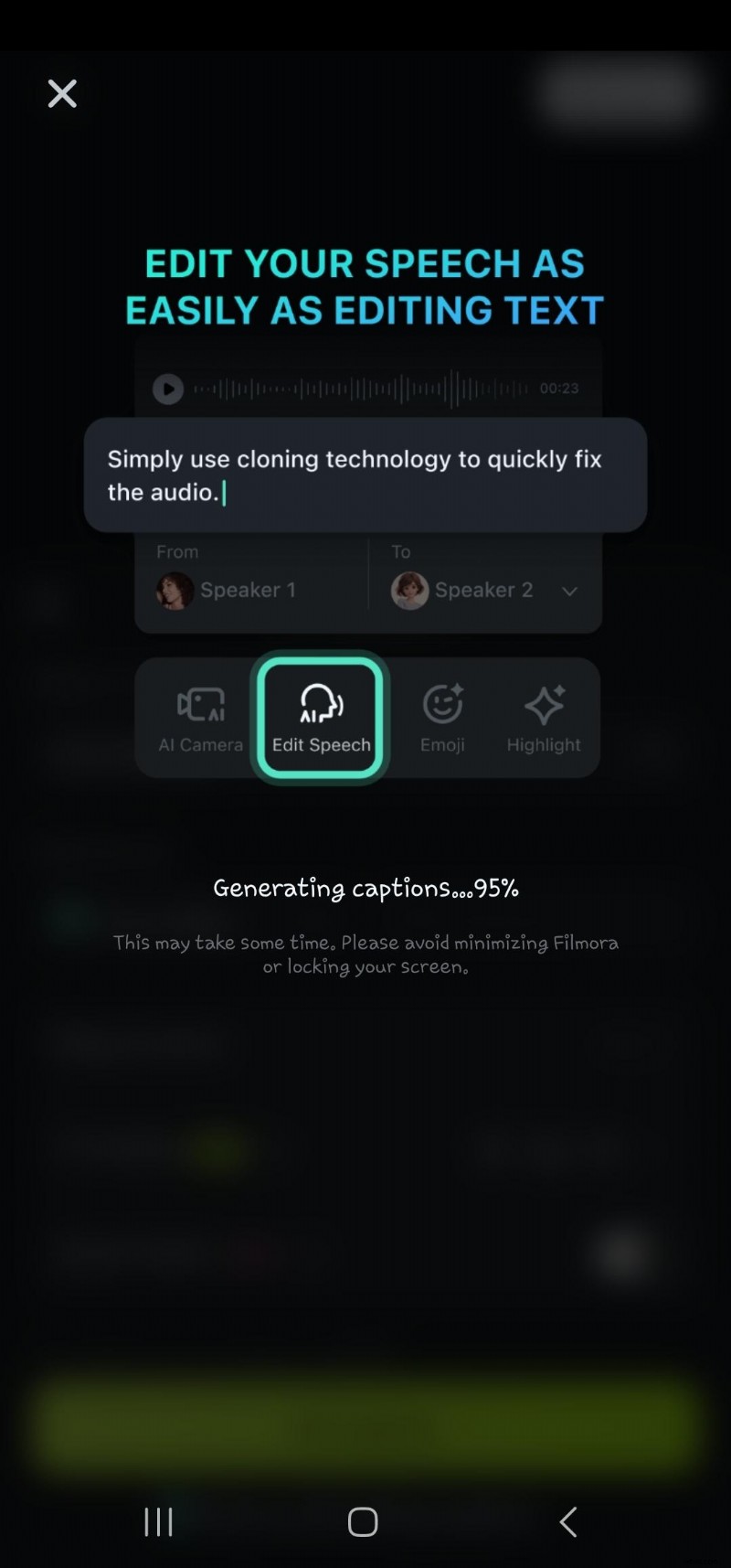
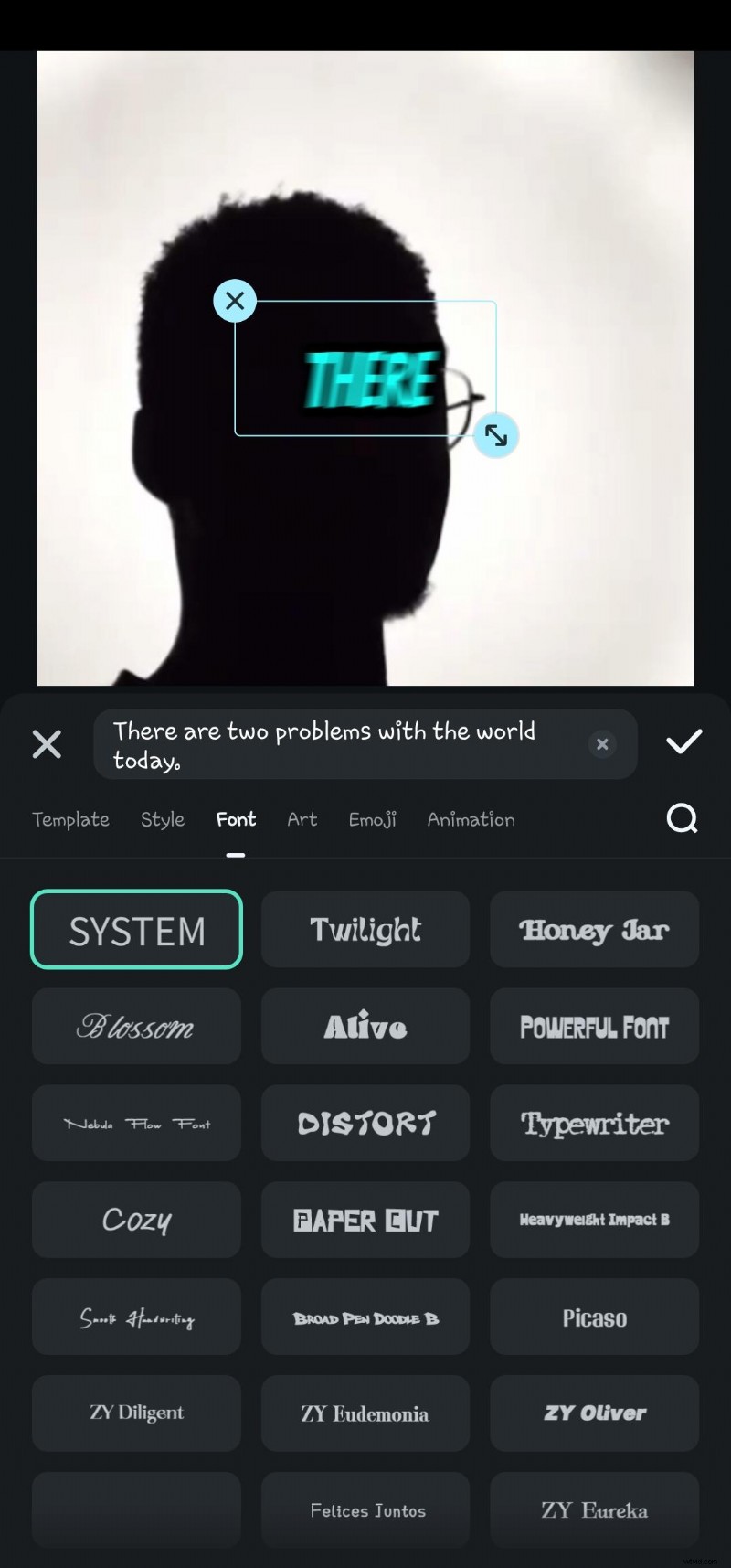
- Étape 6 :double-cliquez sur le texte généré dans la chronologie pour accéder à l'option de modification du discours. Ici, vous pouvez ajouter une animation, modifier le modèle de texte, la police, le style, l'art, etc.
- Étape 7 :Exporter la vidéo
Remarque :Vous devez comprendre que la reconnaissance du locuteur Python donne un contrôle total sur l'entraînement du modèle. Mais Filmora propose une approche automatisée. Sa fonction IA garantit une reconnaissance efficace des locuteurs sans les complexités de programmation.
Partie 4 :Où puis-je utiliser les applications de reconnaissance du locuteur ?

La reconnaissance des locuteurs en Python transforme sans aucun doute diverses industries. Cette technologie offre un moyen rapide et fiable d'identifier les voix dans les vidéos ou les fichiers audio. Cela devient un élément fondamental de différentes industries. Vous trouverez ci-dessous les domaines dans lesquels ces applications sont applicables.
- Assistants intelligents et appareils à commande vocale. Des applications comme Siri, Alexa et Google Assistant utilisent l'identification du locuteur pour distinguer les voix. Cela permet des réponses personnalisées, un accès sécurisé et des commandes vocales personnalisées pour différents utilisateurs.
- Sécurité et authentification vocale. De nombreuses entreprises utilisent l'identification du locuteur pour vérifier les utilisateurs et prévenir la fraude. Il élimine la dépendance aux mots de passe tout en améliorant la protection des données et le confort de l'utilisateur.
- Transcription et notes de réunion basées sur l'IA. La reconnaissance des locuteurs aide des applications comme Otter.ai à différencier les locuteurs. Cela augmente la précision de la transcription, en particulier celles comportant plusieurs notes vocales.
- Centres d'appels et support client. Les centres d'appels utilisent la reconnaissance du locuteur en Python pour améliorer l'authentification et la détection des clients. Les systèmes basés sur l'IA identifient les appelants par la voix, réduisant ainsi le besoin de vérification manuelle de l'identité. Cela améliore la sécurité, l'efficacité et les temps de réponse du service client.
- Soins de santé et accessibilité. Les hôpitaux et les applications de soins de santé utilisent l'identification du locuteur pour une authentification sécurisée des patients. Les outils d'IA basés sur la voix aident les personnes à mobilité réduite à accéder aux appareils sans interaction physique. La reconnaissance des locuteurs Python garantit un accès médical sécurisé et améliore les soins aux patients.
Conclusion
Python est l'un des langages les plus populaires pour l'identification du locuteur et de la voix. Il fournit des bibliothèques puissantes telles que SpeechRecognition, PyAudio, Librosa et Pico Voice Eagle SDK.
Ces outils permettent une identification des locuteurs en Python avec une grande précision et en temps réel. . Cela en fait la meilleure option pour les développeurs, les chercheurs en IA et les applications de sécurité. Filmora offre une alternative plus simple pour ceux qui n'ont pas de compétences en programmation. Il permet la conversion parole-texte, l'édition vocale et la reconnaissance du locuteur sans nécessiter de codage Python.
Essayez les outils basés sur l'IA de Filmora pour l'édition et la transcription automatiques de la voix. Ils rendent le processus rapide et convivial.

Filmora
⭐⭐⭐⭐⭐
Le meilleur logiciel et application de montage vidéo basé sur l'IA